DevOps and Site Reliability Engineering (SRE) sit, in both practice and philosophy, very close to each other in the overall landscape of IT operations. This article explores both disciplines, and their similarities, and defines the role of SRE in the Federal government’s IT operations.
Site Reliability Engineering (SRE) Origins – Just Google It
“Hope is not a strategy.” – Traditional SRE saying
SRE was created at Google around 2003. As one of the largest web companies, it processed over 18M queries a day despite most users still on dial-up. Approximately a year later in 2004, this surged to above 200M queries…and by April, Google announced its IPO.
Google was also one of the earliest companies truly challenged with global reliability demands and its position at the frontier of the 21st Century required them to define how to establish a massive, distributed infrastructure that minimized downtime and latency. Ben Trenor Sloss, Google’s Vice President of Technical Operations at the time, was tasked with creating a team who could ensure the technology behemoth’s websites were scalable, reliable, and efficient. His solution? Site Reliability Engineering (SRE).
Sloss introduced the concept of SRE as an engineering practice, crediting its invention to “what happens when you ask a software engineer to design an operations team.” Currently, it serves as the underlying engineering foundation that supports everything from Google’s internal software infrastructure to user services like email and ads and its cloud platform. In 2003, it served them well in preparing to go bigger and go public a year later.
What is SRE?
SRE applies software as a tool to manage large systems so its maintenance is sustainable for system administrators (sysadmins) at scale – it treats all problems as a software problem. By using tools to manage systems and automate operation tasks, SRE engineers split their time between the remaining operations tasks and development tasks like feature enhancements and automation implementation to improve and maximize reliability. The objective is not to provide 100% reliability but to expect and plan for failures.
Since its adoption, other technology companies have since adopted the practices and principles Google’s SRE team developed to manage their systems effectively. Many of these businesses have contributed significantly to developing and disseminating SRE best practices; Facebook established an SRE team by 2010, Netflix by 2016, and LinkedIn followed a year later.
| SRE Motto: Automate Away Identify any opportunity for automation and their conditions, and do so… |
The following concrete principles define SRE:
- Operations is a Software Problem: Software engineering should be applied to not only traditional software problems but also automating processes and business problems.
- Guided by Service-Level Agreements (SLAs): SRE focuses on reliability and availability, working backwards from their service commitment to the users to define the requirement details of system reliability using Service Level Objectives (SLOs) and Service-Level Indicators (SLIs).
- Manage by Service Level Objectives (SLOs): SLOs specify the level of service requirements (e.g.: availability) over a period of time, a target for the teams to manage against by monitoring SLIs, which measure whether the systems have been running within SLO (e.g.: availability percentage).
- Work to Minimize Toil: If a machine can perform a task, then a machine should. Treating problems as solvable by software means identifying opportunities to automate tedious, manual, or recurring tasks and continuously improving automation in place to re-invest human capacity towards higher value efforts.
Chicken or Egg: DevOps and SRE
Unlike the timeless causality dilemma of the Chicken or Egg, there is a clear answer: SRE. DevOps was not introduced until about 2007.
IT organizations often are compressed with meeting the objectives of the business while operating in an environment with aging infrastructure, changing technologies, and fierce competition for resources. User expectations and usage demands continue to rise along with the complexity of these environments. Moreover, the enterprise world, particularly the public sector, often treats operations as a cost center while increasing its expectations of speed and quality of service and product delivery.
IT practitioners created solutions centered around efficiency to these problems and have coalesced around two disciplines: maximizing operations reliability (SRE) and eliminating collaboration impediments between development and operation functions (DevOps).
Contributions to Efficiency and Resiliency
While industry refers to both disciplines as generally being related to each other as a domain of information technology and software operability, there are also significant differences.
DevOps is a loose set of practices, guidelines, and culture designed to break down silos in IT development, operations, networking, and security. The results of this shifts traditional IT and developer operations to advocate for a culture shift between developers and operations where collaboration Is key, collective ownership of a product is encouraged, accidents are accepted, and tooling and software are changed in an incremental and measured manner. This shift is a departure from traditional IT operations where the development organizations and IT operations did not take collective ownership of an application once it moved from “Dev” to “In Production.”
On the other hand, the SRE plays a critical role in the performance potential of the products from DevOps. The DevOps team streamlines changes and SRE ensures these changes do not increase failure rates – both working to elevate the user experience and organizational efficiency. SRE focuses on creating a highly reliable, scalable, and efficient foundation capable of handling high traffic volume without compromising user experience. Proper SRE practices include proactive prevention of failures and interruptions, leveraging automation to reduce manual intervention, and investing in iterative and continuous improvements towards toil-cutting automation to achieve optimal infrastructure operations.
Particularly during periods of increased demand, such as natural disasters or responding to large-scale cyber attacks, government services are required to scale rapidly to meet citizens’ needs and protect American interests. SRE positions government to scale efficiently at range and during peak demand periods to provide essential services and better serve its citizens and strengthen public trust.
How SRE Matters
An effective IT operations team utilizing SRE’s principles and framework can improve the performance of an IT organization, meet its organization’s availability needs and improve developer output while lower the cost of operations. Rather than scaling their human capital to meet the demand for new systems, Federal IT managers expect to see that investment into their IT teams become more effective and scale sub-linearly rather than linearly if continued investment of SRE principles and automation are successfully implemented. This approach to investing in your operations drives higher efficiency at lowered costs.
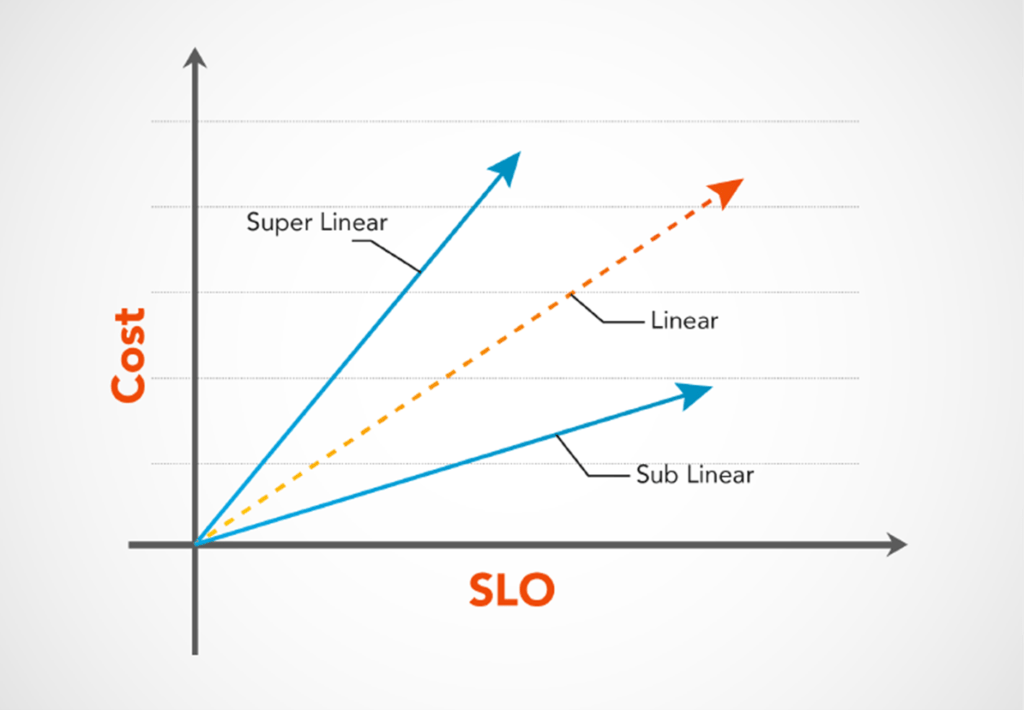
The Role of SRE for Government
While many commercial businesses have the option to expand human capital investments, government is constrained by tight budgets, long procurement cycles, and critical response times to meet mission objectives. SRE practices provide federal agencies the ability to forgo linear expansion, maximize the capacity of their existing human capital, and optimize the value of other investments. For example, applying SRE practices to analyze and monitor cloud resource utilization can help a government agency establish an accurate baseline and automate utilization pattern reports based on thresholds. From there, the team can develop dynamic scaling policies and right-size resource allocation based on utilization to both reduce expenses from maintaining idle infrastructure and optimize cloud resource usage.
Federal agencies continue to expend significant amounts of their annual budget towards IT O&M despite the larger initiative towards modernization and digital transformation. Venkatapathi “PV” Puvvada, NetImpact CEO, explores in his NextGov feature how integrating SRE into tech operations can reduce toil throughout these digital transformation initiatives.
My Agency is Ready for SRE
NetImpact has the most comprehensive approach to accelerating our clients’ digital dexterity journey. Applying modern best practices and our DX360°® emergent solutions, NetImpact optimizes the entirety of your operational environments (including on-premise, IaaS, PaaS, and SaaS), delivery platforms, pipelines, existing and planned systems, Cloud management and AWS services, and application automation.
Contact us today to learn about our self-service and idempotent automation capabilities and how we’re designing self-healing and immutability infrastructure for customers like the Department of Agriculture.
